01はじめに
このカリキュラムの目的はSQLの基本を押さえて、基本的なデータ操作が行えるようになることです。
初めのうちはイメージがつきにくいと思うので、最初から深く理解できなくても問題ありません。
SQLはカリキュラム内にいくつか記載されていますので、実際にSQLを書いて動きの確認をしていきましょう。
02SQLとは?
データベース(DB)とやり取りするときに使う言語のひとつです。
データベースに保存されているデータの中から、必要となるデータを抽出したいとき、不要なデータを削除したいとき、データを追加・更新したいときに使用します。
03データベース(DB)とは?
データベース(Database)とは、データを効率的に管理・保存するための仕組みであり、テーブル(Table)はデータベース内でデータを表のように格納しています。
データベースは「データを入れておく箱」のようなもので、下のような図(テーブル)のデータが何個もあるイメージを持っていただけるとわかりやすいかと思います。
データベース(DB)を使用するメリット
データベースに存在するデータの量は膨大で、1つのシステムでも何百のテーブルが使われることもあります。
下記の図が1つのテーブルになります。(従業員テーブル)
図のように整理された情報は扱いやすく、必要なときに必要なデータをすぐに取り出せる点が最大のメリットです。
ex) 従業員テーブル
| id | name | old | department |
| 1 | 村田 | 27 | AS |
| 2 | 矢野 | 24 | OFS |
| 3 | 熊田 | 18 | OFS |
テーブルの構成
次にテーブルを構成するレコード、カラム、フィールドについて細かく見ていきます。
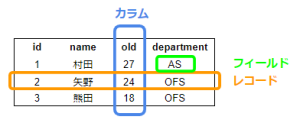
レコード
レコードはテーブルの行に該当し、データそのものを意味します。
上図のオレンジの枠の範囲をレコードと呼び、1レコード=1件のデータということになります。
カラム
カラムはテーブルの列に該当し、属性を意味します。列ごとにデータ型が決められ、データ型にあったデータでないと、格納することができません。また、カラムごとに値を検索するための索引や、「Null値(空)は入力できない」といった制約をつけることができます。
また、列名のこと、あるいは項目名のことをカラム名と言います。
上記の従業員テーブルを用いて説明すると、id、name、old、departmentが「カラム名」となります。
フィールド
フィールドは、レコードの中の項目であり、データの最小単位です。表計算ソフトなどの「セル」に該当し、値が格納される場所になります。
環境構築を行う
実際にSQLを発行するにあたり、必要となる環境の構築を行いましょう。
AWS Cloud9でMySQLを利用するための準備を行います。
MySQLにログインし、データベースを作成する
下記は、MySQLデータベースにルートユーザーとしてアクセスするためのコマンドです。
今後、Cloud9でSQLを発行したいときは下記のコマンドを実行して、MySQLにアクセスしておく必要があるので、覚えておきましょう。
sudo mysql -u root上記のコマンドを実行することで「mysql>」が表示された状態になります。SQLを実行するときはこの状態で実行しましょう。
下記のコマンドを実行してデータベース「lesson」を作成します。
CREATE DATABASE lesson;
データベースが作成されたかどうか確認をするため、下記のコマンドを実行しましょう。
show databases;
操作したいデータベースを選択しましょう。
USE lesson;下記のコマンドを実行してデータベース「lesson」を作成します。
CREATE TABLE `lesson`.`M_EMPLOYEE` (
`id` int(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'ID 自動インクリメント',
`name` varchar(20) NULL DEFAULT NULL COMMENT '名前',
`old` int(11) NULL DEFAULT NULL COMMENT '年齢',
`department` varchar(20) NULL DEFAULT NULL COMMENT '所属部署',
PRIMARY KEY (`id`)
) ENGINE = InnoDB DEFAULT CHARSET = utf8 COMMENT = '従業員テーブル';テーブルの確認
実際に上記コマンドを実行した結果、テーブルが作成されたか確認しましょう。
テーブルの一覧は下記のコマンドを実行します。
show tables;
データの挿入
従業員テーブル「M_EMPLOYEE」の作成が終わったら、データを入れましょう。
INSERT INTO `lesson`.`M_EMPLOYEE`
(name, old, department)
VALUES
('村田', '27', 'AS'),
('矢野', '24', 'OFS'),
('熊田', '18', 'OFS'),
('村田', '18', 'OFS'),
('西村', NULL, 'OFS');以上で、環境構築は完了です。
SQLを学ぼう
次は、SQLの基本構文を学びながら、動きの確認をしていきましょう。
今後、「クエリ」という言葉を聞くことになると思いますが書いたSQLのことをクエリ(query)と言います。
04SQLの基本構文
SQLを使った命令の基本的な書き方は、以下の通りです。
検索は「SELECT」を、追加は「INSERT」を、更新は「UPDATE」を、削除は「DELETE」を、それぞれ使います。 「FROM」に続けて取得対象のテーブルを指定します。 「WHERE」以降は処理対象のデータを指定する条件文です。
実際に作成したテーブルで実行してみましょう!!
05SQLの基本的なCRUD操作
データの検索 SELECT文
データを抽出したいときに使います。
例えば「従業員テーブル」に存在する全てのカラムのデータを抽出したいときは以下のように書きます。
①カラム名を全て入れてSELECT
SELECT
id,
name,
old,
department
FROM `lesson`.`M_EMPLOYEE`;上記のようにカラム名を記述することで、取得したいカラム名のデータを抽出することができます。
今回の場合、すべてのカラム名を記述しているので、すべてのカラムのデータを取得できます。
②カラム名は記載せず「*」を使用することですべてのカラムを選択
SELECT * FROM `lesson`.`M_EMPLOYEE`;上記2つの①②のSQLを実行した結果、両方とも以下のように同じデータが抽出できます。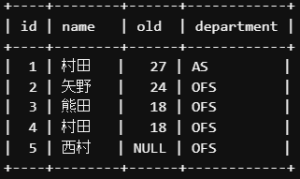
これから、SELECTしたデータを見ていきます。
| id | name | old | department |
| 1 | 村田 | 27 | AS |
| 2 | 矢野 | 24 | OFS |
| 3 | 熊田 | 18 | OFS |
| 4 | 村田 | 18 | OFS |
idと記載されているカラムを確認しましょう。
このカラムは他と重複しない「主キー」と呼ばれるものになります。
そのレコードが「一意のデータ」であることを判別するためのカラムになります。
NULL
idが5であるレコードを見てみましょう。oldカラムがNULLとなっています。NULLとはデータが格納されておらず、未定義の状態を言います。
NULLを判定する方法は少し特殊で、以下のように「IS NULL」を使います。
SELECT *
FROM lesson.M_EMPLOYEE
WHERE old IS NULL;
-- oldカラムがNULLのレコードを取ってきて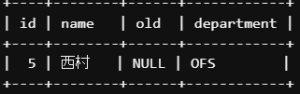
oldカラムにNULLが入っているレコードが抽出できました。
特定のデータの抽出
テーブルのすべてのレコードを抽出するのではなく特定のデータを抽出したいときのクエリの書き方になります。
例えば名前が「村田」という人のデータが欲しいときは以下のようにWHERE句を使って書きます。
SELECT *
FROM `lesson`.`M_EMPLOYEE`
WHERE name='村田';
-- 文字列を扱うときはクォーテーションで囲みましょう
-- nameカラムが村田のレコードを取ってきて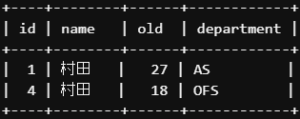
これはWHEREの条件に合ったカラム、つまり「name」が’村田’のものを取ってくるという条件を加えたものになります。
| id | name | old | department |
| 1 | 村田 | 27 | AS |
| 4 | 村田 | 18 | OFS |
このようにWHEREは欲しい条件のデータを取得することができます。
WHERE句とは、テーブルデータの検索条件を指定するためのSQL構文です。
WHERE句を使う目的は、データの検索対象をしぼりこむためにSELECT文と組み合わせたり、データの更新対象を指定するためにUPDATE文やDELETE文と組み合わせて使います。
データの追加 INSERT文
INSERT INTO テーブル1 (項目1, 項目2) VALUES(‘値1’, ‘値2’);
データの更新 UPDATE
UPDATE テーブル1 SET 項目1 = ‘値1’, 項目2 = ‘値2′ WHERE項目3=’条件1’;
データの削除 DELETE
DELETE FROMテーブル1 WHERE 項目3=’条件1′;
06論理削除と物理削除
データベースにおいて、「論理削除」と「物理削除」は、データを削除する二つの方法があります。
論理削除は、データをデータベースから完全に削除するのではなく、削除フラグなどの方法でマークし、削除されたように見せる方法です。つまり、データはまだデータベースに存在しますが、削除されたものとして扱われます。この方法は、データの復元が必要な場合に有用です。たとえば、誤ってデータを削除してしまった場合や、削除する前にデータを確認する必要がある場合などです。
一方、物理削除は、データを完全に削除する方法です。つまり、データはデータベースから完全に消去されます。この方法は、データの復元が不可能であるため、削除する前に注意深く確認する必要があります。物理削除は、データベースの容量を開放するために使用されます。ただし、この方法は、誤ってデータを削除してしまった場合や、復元する必要がある場合には使えません。
簡単に言えば、論理削除は「見えないように隠す」方法であり、物理削除は「完全に消去する」方法です。どちらの方法を使用するかは、データの保持期間や再利用の可能性など、そのデータの要件によって異なります。基本的に論理削除を使うようにしておけば良いと思います。
07演算子
データベース内のデータを操作し、条件を指定するために使用される演算子というのもがあります。
今回の場合、テーブルに’村田’と名前のつく人が2名います。
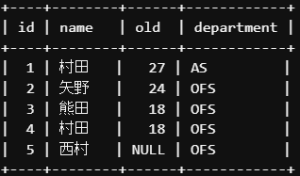
部署が’OFS’の村田のデータを取りたい場合、「AND演算子」を使って条件を絞る必要があります。
SELECT *
FROM `lesson`.`M_EMPLOYEE`
WHERE name='村田'
AND department = 'OFS';
-- nameが村田でdepartmentがOFSのレコードを取ってきてA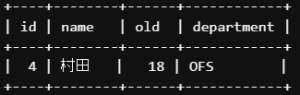
他にも「OR演算子」というものがあります。
名前が矢野、または熊田のデータが欲しいときは以下のように記述します。
SELECT *
FROM `lesson`.`M_EMPLOYEE`
WHERE name='矢野'
OR name= '熊田';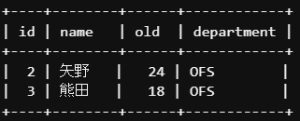
その他にも演算子は様々あります。よく使われるものばかりですので使えるようにしておきましょう。
| 演算子 | 使用例 | 意味 |
| IS NULL | a IS NULL | a はNULL |
| IS NOT NULL | a IS NOT NULL | a はNULLではない |
| IS | a IS boolean_value | a はboolean_value |
| IS NOT | a IS NOT boolean_value | a はboolean_valueではない |
| BETWEEN AND | a BETWEEN min AND max | a は minより大きいか等しくmaxより小さいか等しい |
| NOT BETWEEN AND | a NOT BETWEEN min AND max | NOT (a BETWEEN min AND max)のこと |
| IN | a IN (value,…) | a は 括弧内のいずれかの値に等しい |
| NOT IN | a NOT IN (value,…) | a は 括弧内のいずれの値とも等しくない |
| LIKE | a LIKE pat | SQL の単純な正規表現比較を使用したパターンマッチング |
| NOT LIKE | a NOT LIKE pat | LIKEの結果を反転させたもの |
| 演算子 | 使用例 | 意味 |
| = | a = b | a と b は等しい |
| <=> | a <=> b | a と b は等しい(NULL対応) |
| <> | a <> b | a と b は等しくない |
| != | a != b | a と b は等しくない |
| < | a < b | a は b よりも小さい |
| <= | a <= b | a は b よりも小さいか等しい |
| > | a > b | a は b よりも大きい |
| >= | a >= b | a は b よりも大きいか等しい |
08マスタテーブルとトランザクションテーブル
プログラミングをしていく上で「マスタ」という言葉はよく使います。
それと相対する「トランザクション」という言葉もあります。
それぞれの言葉について説明していきます。
マスターデータ
何かの基礎となるデータ。システムを使う最初の段階から入ってないと困るデータ。
例えば、出退勤管理システムであれば、従業員の情報などにあたります。
従業員の情報がないと誰が出勤してきたのか判断できません。このようにシステムを使い始める時点でシステムの中に入っているデータを指します。
トランザクションデータ
システムを使うことで蓄積されていくデータ。
出退勤管理システムであれば、出退勤の情報などです。
出退勤の情報は、最初は出退勤管理システムの中にありません。
ただ、出退勤システムを使うことで毎日、似たようなデータがたくさん増えていきます。
このようにシステムを使っていると増えていくデータをトランザクションデータと言います。
もし、マスタデータが無い場合にどうなってしまうのか?
まず、どの従業員のデータが正しいものなのか分かりませんし、一覧性に欠けますよね。
また、既に出退勤に登録済のデータがある中で部署が変わってしまった、名前が変わってしまったということが起こるかもしれません。
その場合に出来てしまった大量のデータを編集する必要がでてきます。そのようなことを防ぐために、マスタテーブルは存在します。
実際にテーブルを作ってみる
マスタテーブル(従業員テーブル)は既に作っているので、トランザクションテーブル(給料テーブル)を実際に作ってみる。
給料テーブル(トランザクションテーブル)
CREATE TABLE `lesson`.`T_SALARY` (
`id` int(11) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT 'ID 自動インクリメント',
`m_employee_id` int(11) NULL DEFAULT NULL COMMENT '従業員マスタID',
`money` int(11) NULL DEFAULT NULL COMMENT '給料',
`year` int(11) NULL DEFAULT NULL COMMENT '年',
`month` int(11) NULL DEFAULT NULL COMMENT '月',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8
COMMENT = '給料テーブル';m_employee_idはM_EMPLOYEEのidの事です。
→「外部キー」と呼ばれるものです。
外部キーは、M_EMPLOYEEテーブルとT_SALARYテーブルを合わせて使いたい時に使用します。
これにより、データベース内のテーブル間の関連性を確立し、データの整合性を維持するのに役立ちます。
試しに2023年の1、2月のデータを入れてみました。
INSERT INTO `lesson`.`T_SALARY`
(m_employee_id, money, year, month)
VALUES
(1, 200000, 2023, 1),
(2, 300000, 2023, 1),
(3, 900000, 2023, 1),
(1, 210000, 2023, 2),
(2, 310000, 2023, 2),
(3, 910000, 2023, 2);以上が、マスタテーブル、トランザクションテーブルの使い分けです。
とても重要なので覚えておきましょう。
09集計とグループ化
データベース内のデータをクエリして集計する際に、GROUP BY句を使用してデータをグループ化することができます。これは、特定の列の値に基づいてデータをまとめて集計するために使用されます。
給料テーブルを見てみましょう。
SELECT * FROM lesson.T_SALARY;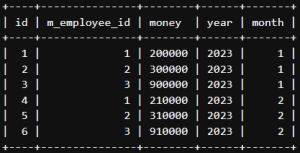
例えば、上記の給料テーブルにて、従業員ごとに2023年度の給料の合計値を出したい場合は以下のように記載します。
SELECT
SUM(money) as employee_saraly,
m_employee_id -- 誰のデータかわかるように従業員IDも取得しておく
FROM `lesson`.`T_SALARY`
WHERE year = 2023
GROUP BY m_employee_id; -- 従業員毎にグループ化このクエリは、従業員ID(m_employee_id)を基準にして給料データをグループ化し、各従業員の合計金額を計算します。結果は次のようになります。
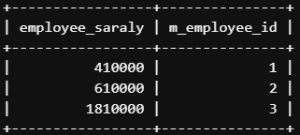
このように、GROUP BY句を使用することでデータを要約し、集計することができます。従業員ID(m_employee_id)ごとの合計金額がわかりやすく表示されています。
グループ化と合わせて良く使われる集計関数と使い方一覧
以下はよく使用される集計関数の一部です。
1.COUNT関数
- 指定された列の非NULL値の数をカウントする
- 例: SELECT COUNT(column_name) FROM table_name;
2.SUM関数
- 指定された列の数値の合計を計算する
- 例: SELECT SUM(column_name) FROM table_name;
3.AVG関数
- 指定された列の数値の平均を計算する
- 例: SELECT AVG(column_name) FROM table_name;
4.MAX関数
- 指定された列の最大値を取得する
- 例: SELECT MAX(column_name) FROM table_name;
5.MIN関数
- 指定された列の最小値を取得する
- 例: SELECT MIN(column_name) FROM table_name;
これらの関数は、GROUP BY句と組み合わせて使用することで、グループごとに集計することができます。GROUP BY句は、指定された列の値で行をグループ化するために使用されます。
複数テーブルの結合を行う
SQLでは、複数のテーブルを結合することができます。テーブルを結合することで、異なるテーブルのデータを結合して1つの結果セットにすることができます。
テーブルを結合するには、JOIN句を使用します。JOIN句は、結合するテーブルの列を指定して、2つ以上のテーブルを結合することができます。
以下は、よく使用されるJOIN句の種類です。特にINNER JOINとLEFT JOINはよく使います。
1.INNER JOIN
- 2つのテーブルの共通する列に基づいて、テーブルを結合する
- 例: SELECT * FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;
2.LEFT JOIN
- 左側のテーブルのすべての行と、右側のテーブルのマッチする行を結合する
- 例: SELECT * FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name;
3.RIGHT JOIN
- 右側のテーブルのすべての行と、左側のテーブルのマッチする行を結合する
- 例: SELECT * FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name;
4.FULL OUTER JOIN
- 2つのテーブルのすべての行を結合する
- 例: SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.column_name = table2.column_name;
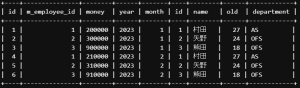
以下は、2つの従業員マスタテーブルと給料テーブルをINNER JOINで結合する例です。
SELECT *
FROM `lesson`.`T_SALARY`
INNER JOIN `lesson`.`M_EMPLOYEE` ON T_SALARY.m_employee_id = M_EMPLOYEE.id;
-- T_SALARYテーブルには従業員マスタテーブルの情報を参照したいのでm_employee_idを持たせています。この例では、”T_SALARY”テーブルと”M_EMPLOYEE “テーブルを、”m_employee_id “列を共通列としてINNER JOINで結合しています。結合する列を指定することで、2つのテーブルの関連するデータを結合することができます。
終わり
以上が絶対に抑えておいてほしいSQLの内容になります。
今回はよく使う重要なところだけをさらっと学びましたが、この業界にいる限りクエリを書く機会はとても多いです。
今はマスターできなくても、調べて書けるようにになれば問題ありません。
10課題
今使っているlessonデータベースをそのまま使ってください。
実際にSQLの実行までやってみましょう。
1.新たに従業員が5人入社しました。情報に照らし合わせて、該当するテーブルに追加してください。なお、T_SALARYテーブルに追加する際は、誰の給料か分からなくなってしまうのでM_EMPLOYEEに追加されたそれぞれの従業員のidを入れるようにしてください。
(T_SARALY.m_employee_id = M_EMPLOYEE.id)
| name | old | department | money | year | month |
| 今西 | 23 | AS | 400000 | 2023 | 2 |
| 黒島 | 32 | AS | 150000 | 2023 | 2 |
| 佐々木 | 47 | OFS | 500000 | 2023 | 2 |
| 竹村 | 25 | OFS | 500000 | 2023 | 2 |
| 手塚 | 28 | AS | 400000 | 2023 | 2 |
2.下記2名の部署が変更となりました。情報に合わせて変更してみましょう。
| name | department |
| 手塚 | デザイン |
| 矢野 | AS |
3.OFSだけの平均年齢と最高給与を算出することにしました。OFSに所属する従業員の平均年齢と2023年2月の最高給与をOFSのみで算出してください。
| name | old | money | year | month |
| 西村 | 41 | 800000 | 2023 | 2 |
| 佐々木 | 25 | 追加不要 | 追加不要 | 追加不要 |
| 村田 | 28 | 200000 | 2023 | 2 |
コメントを残す